Encodings are the worst
{kind=link}
These past few weeks I seem to keep on running into issues where things have been really bad about handling character encodings.
Back in the day, encodings were an absolute nightmare. You had different 8-bit encodings for every language, each with a bunch of different ISO standards; a very commonly-used one is ISO-8859-1, aka Latin-1, which is basically the characters needed to render all of English and most of several Romance languages (although a bunch of stuff is missing), plus a little extra stuff for math, scientific notation (µ), and German (ß), as well as a bunch of miscellani which were generally useful.
Unfortunately, a lot of Internet standards decided to default to that, including HTML.
Note: There are some updates based on feedback at the very bottom.
Nowadays we have Unicode, and the UTF-8 encoding which is pretty much universally-supported – and yet a lot of things still default to ISO-8859-1. UTF-8 is designed such that it has some basic error detection in it, which is incredibly useful for detecting when something isn’t UTF-8 and therefore needs to be converted, usually with a bunch of heuristics to determine what it should be converted from.
Unfortunately, a lot of things seem to assume that everything (even already-UTF-8 data) is ISO-8859-1 and “helpfully” convert it to UTF-8, so as a result you end up with characters like a properly-encoded é turning into é, which something else then interprets as “really” being CP1251 so it becomes ГѓВ©, and so on. Often these multiple layers of “correction” happen within the database during various schema migrations or version upgrades or the like, making disentangling the root problem all but impossible.
What’s even more fun is HTML is in this weird spot where the earliest standards didn’t specify an encoding, later on they decided it would be ISO-8859-1 by default, with some rather complicated logic to override it.
HTML 5 finally fixed that in the standard by indicating that an HTML 5 document – meaning, something with a Update: This was incorrect, please see below.<!DOCTYPE html> at the top – is UTF-8. But I just spot-checked that in Safari, Chrome, and Firefox, and all three of them interpreted an HTML 5 document with no specified encoding but plenty of valid UTF-8 symbols as being ISO-8859-1.
Yesterday I found out that many, many French-language websites simply do not accept accents in peoples' names, either rejecting it as a validation error or corrupting it into mojibake, if not outright crashing. Because so many people building web apps don’t think to declare a character encoding, and then someone fills out a form and the browser says “Oh this document is in ISO-8859-1 so therefore so should my form response” and then it sends some invalid codepoints that trip up UTF-8’s built-in error detection. So web programmers have decided it’s easier to just stick to 7-bit ASCII for everything.
Or, there’s a lot of bad advice out there about making all of your webpages 7-bit clean and only using HTML entities like é or, worse, é in your resulting document. Which means that simple Japanese text like 「おはようございます」 must be encoded as 「おはようございます」 which means that if you need to view the page source, you’re… kinda screwed.
This is one of those software things where I wish we could just do a clean restart and drop all the weird compatibility layers, to heck with legacy stuff. And I mean, HTML 5 was supposed to do that, and yet,
<!DOCTYPE html> <html><head> <title>Heñlo cuties!</title> </head><body> <h1>Hello everyone!</h1> <p>How is your day going? 😃</p> </body> </html>
looks like this:
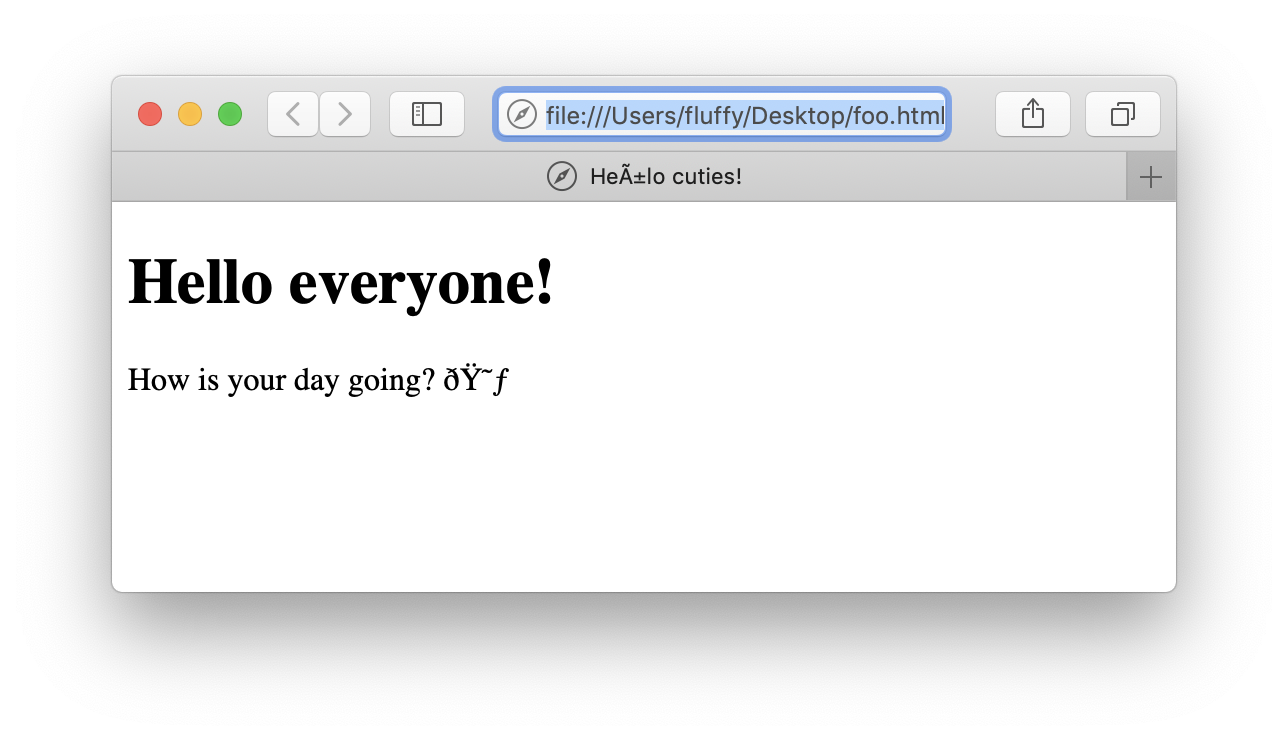
Note that this was served as a local file to Safari on macOS 10.14, which is probably the most Unicode-native platform I know of! If even macOS can’t get it right, I think we’re screwed.
Anyway. I look forward to seeing how things get hecked up when people repost this content elsewhere or even post comments right here, because who knows what Disqus does…
Updates
Apparently the sources I was relying on were mistaken (apparently doing a web search on “HTML 5 default encoding” is not a great way to find the answer, not that the W3C has made the answer easy to find in their own resources); HTML 5 does not specify a default encoding, and the spec is that unless it’s specified it should default to your system encoding. It’s still puzzling that macOS would default to Latin-1 when its system encoding is UTF-8, but whatever. I’m still gonna have Publ continue to provide a UTF-8 default because it does everything else in UTF-8, and if someone really wants to override it they can set the <meta charset> themselves.
Also, some have said that <meta charset> is required for valid HTML 5 but that doesn’t seem to be the case; it just needs to be specified either with that or in the Content-Type header. The W3C guidance is that <meta charset> is preferred rather than relying on the system or webserver encoding, though.
That said, this rant wasn’t entirely about HTML – believe it or not, there’s still other file formats that people use! I keep running into situations where data stored in a database has been stored as UTF-8 and then converted “from” Latin-1 into UTF-8 again, for example, and I’m always seeing questions from inexperienced programmers where they’re seeing similar things happen and it gets very confusing. Not to mention how a lot of technologies use UTF-16LE (without BOM!) as their native encoding instead, and that causes all sorts of fouling-up.
At least it’s rare to have to deal with EBCDIC anymore.
Comments
Before commenting, please read the comment policy.
Avatars provided via Libravatar